

實在沒想到已經 2020 年的這個時候,還會有需要處理 Big5 及 UTF-8/16 編碼的時候。首先先來複習一下各種名詞:
Big5:由於古早時代個人電腦沒有統一編碼標準,資策會在 1983 年主導設計了一套中文編碼,包括 13,053 個字與 441 個符號。Big5 編碼中每個字由 2 bytes 表示,例如「天」這個字的 Big5 碼為 0xA4D1。因有許多常用字未收錄在標準中(例如:伃、啓、堃等),後來衍生出很多套官方及非官方的延伸標準(例如:Big-5E、Big5-2003、CP950、Unicode補完計畫等)試圖解決這些問題。
Unicode:是一套為了解決字元編碼問題而產生的國際標準,在最新版本的 Unicode 13.0 中,已經包含了超過 14 萬個字符。基本上即是盡可能將世界上所有的字都透過一個字碼(code point)來代表,例如「天」這個字可以表示為 U+5929 。但嚴格來說,Unicode 並不是一套「可以直接於數位系統上使用的編碼」,因為 Unicode 本身並未定義 code point 用位元表示時的傳輸格式與方法,因此在不同的規格下,就會產生不同的表示方式。例如於 UTF-8 編碼,「天」這個字會以 e5 a4 a9 表達,UTF-16 下則會以 59 29 表達。
UTF:全稱為 Unicode Transformation Format,是一套用來將 Unicode 所定義的 code point 編碼為特定位元組的方式,常見的編碼方式包含 UTF-8、UTF-16、UTF-32 等。其中 UTF-8 使用 1 至 4 個 bytes (one to four 8-bit bytes)表達一個字,且與 ASCII 編碼相容。UTF-16 使用 2 或 4 個 bytes 表達一個字 (one or two 16-bit code units)。UTF-32 則統一使用 4 個 bytes(a single 32-bit code unit)。
UCS-2:額外提一下 UCS-2,同樣是用來編碼 Unicode 的一種方式,使用 2 個 bytes 表達一個字,因此最多只能包含 65536 個字。因為歷史因素,此編碼仍然在某些軟體或產業中被廣泛採用。另外,可以把 UTF-16 視為基於 UCS-2 的擴充,對於大多數的常用字來說,此兩種編碼是幾乎等價的。
進入正題,台灣集中保管結算所是負責處理台灣證券交易結算交割、保管股票的一個類官方機構。可想而知就跟很多金融系統一樣,這個有著悠久歷史(1989 年成立)的公司,自然也會遇到中文編碼的問題。總而言之,基於集保內部仍有眾多使用 Big5 編碼的系統,為了讓系統記錄股東姓名或公司資料時能正常顯示文字,又為了讓與集保公司溝通的第三方單位可以理解這些文字,集保有在官方網站上釋出了一份「集保罕用字型及對照檔」。

在這個檔案裡面可以看到他包含了幾個 .TTE 造字檔,以及一個 Map_code.txt 字型對照檔。簡單來說,就是集保把一些 Big5 編碼內沒包括到的字,透過造字系統加入到了 Big5 的造字區,並提供了相對應的字型檔。如果你有額外安裝這些字型,這些罕字就可以在你的系統上顯示出來囉。
你說,那沒另外去裝這些造字字型的人呢?那當然就看不到啦。所以基本上這只是一個讓集保及合作廠商/相關機構之間可以正確溝通的變通方式。假設集保的用戶 Y 姓名其中一個字是「啓」,由於這個字不在 Big5 碼的編碼內,集保就把 Big5 造字區(編碼範圍為 0xFA40 – 0xFEFE + 0x8E40 – 0xA0FE + 0x8140 – 0x8DFE)的其中一個編碼:0x994B 指給了「啓」這個字,並將編碼傳送給廠商 A。因為集保有提供對照及字型檔給廠商 A,所以廠商可以明白地知道這個 0x994B 對到「啓」字。但如果廠商 A 今天要把這個訊息再傳到網頁上給其他用戶觀看呢?這時候如果沒有透過自建的編碼轉換,一般網頁瀏覽器是無法正確顯示出這個字的。
幸好,就如同先前提到的,我們可以透過集保提供的 Map_code.txt 這個對照檔,得到每個罕字所對應到的 UCS-2 編碼,並透過一對一對應的方式將文字轉碼後再顯示到網頁上。
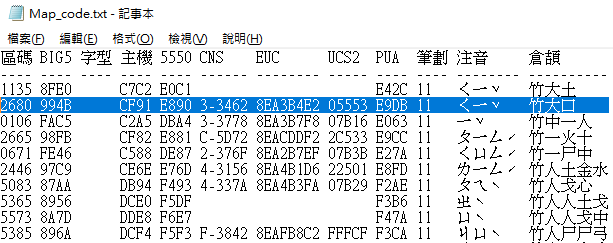
如上圖,可以看到 0x994B 這個字在 UCS-2 編碼是存在的,代碼是 05553(用 Unicode code point 表達就是 U+5553)。因此只要可以把這個字轉為用 UTF-8/16 表達的話,一般人的電腦基本上是可以正常顯示這個字的(就如同現在瀏覽這頁的你可以正常看到這個「啓」字)。當然,仍然有一些極特殊的造字在這個對照表中是沒有對到既有的 UCS-2 編碼的,這種狀況就暫時無解了,但基本上只要完成轉碼,我們可以解決超過九成以上的罕字顯示問題。
具體做法就是透過自定義的一個 mapping table 來把 big5 的自造編碼轉為 UCS-2 編碼,再將此編碼用文字顯示出來:
// define a mapping table
Dictionary<string, string> _mapping = new Dictionary<string, string>()
{
// big5 code, unicode codepoint, string, pinyin
// ...
{ "994B", "05553" }, // 啓 #### ㄑㄧˇ
// ...
};
// get big5 encoding bytes of input
byte[] big5Bytes = Encoding.GetEncoding("BIG5").GetBytes(input);
// transform the bytes to hex format
int big5Value = BitConverter.ToUInt16(big5Bytes, 0);
string key = big5Value.ToString("X");
// find it from the mapping table
if (_mapping.ContainsKey(key))
{
int codepoint = int.Parse(_mapping[key], NumberStyles.HexNumber);
// convert the codepoint to UTF-16 encoded string
// https://docs.microsoft.com/en-us/dotnet/api/system.char.convertfromutf32?view=netcore-3.1
unicodeString += Char.ConvertFromUtf32(codepoint);
}
以上是流程示意,完整的程式碼可以參考這份 gist。還是希望舊系統都能把 Big5 丟掉,趕快轉換到一勞永逸的 Unicode 國際標準啦。
參考資料:
1. https://blog.darkthread.net/blog/tdcc-font-and-big5-eudc/
2. https://www.cns11643.gov.tw/index.jsp
3. https://www.tdcc.com.tw/portal/zh/download
4. https://www.twilio.com/docs/glossary/what-is-ucs-2-character-encoding
5. http://big5.bod.idv.tw/home/big5-unicode-cns11643